Specific formats are required to load your benchmark data to IOHanalyzer. If your data sets are generated in the format of
- COCO/BBOB data format as regulated in https://hal.inria.fr/inria-00362649,
- Nevergrad data format (explained in https://github.com/facebookresearch/nevergrad), or
- IOHprofiler data format, which is motivated and modified from COCO data format,
then you could skip this section. Needless to say, you are encouraged to convert your own benchmark data to the format regulated here!
CSV-based data structure
From IOHanalzyer version 0.1.7, a new option for data format has been included. This allows you to upload a csv-file containing your performance data, which offers more flexibility than the format described below. To use this functionality on the GUI, the checkbox ‘use custom csv format’ should be enabled. This then allows for uploading of the csv-file, which loads the column names. The names can be arbitrary, and will be matched to the following:
- Evaluation counter: This should denote the evaluation number at which the data was recorded. If this is not included or set to ‘None’, it is assumed that all evaluation counts per run are sequential.
- Function values: The actual performance data. This is the only required column.
- Function ID: A column which denotes the function name or identifier on which the run was performed. If set to ‘None’, it is assumed all runs are on the same function (whose identifier can then be entered manually).
- Algorithm ID: A column which denotes the name or identifier of the algorithm with which the run was performed. If set to ‘None’, it is assumed all runs are from the same algorithm (whose identifier can then be entered manually).
- Problem dimension: A column which denotes the dimension of the problem on which the run was performed. If set to ‘None’, it is assumed all runs are on the same dimensionality (which can then be entered manually).
- Run ID: A column which denotes the name or identifier of the run which was performed. If set to ‘None’, it is assumed that only one run is performed on each function / dimension / algorithm combination.
Finally, a checkbox indicates whether the problem is minimization or maximization. The selected settings can then be used to process the full uploaded csv file.
File Structure
In general, when benchmarking IOHs on several test functions/problems and dimensions, the raw data files are grouped by the test function and stored in sub-folders (the same with the COCO/BBOB data format). For example, one example file structure is outlined as follows:
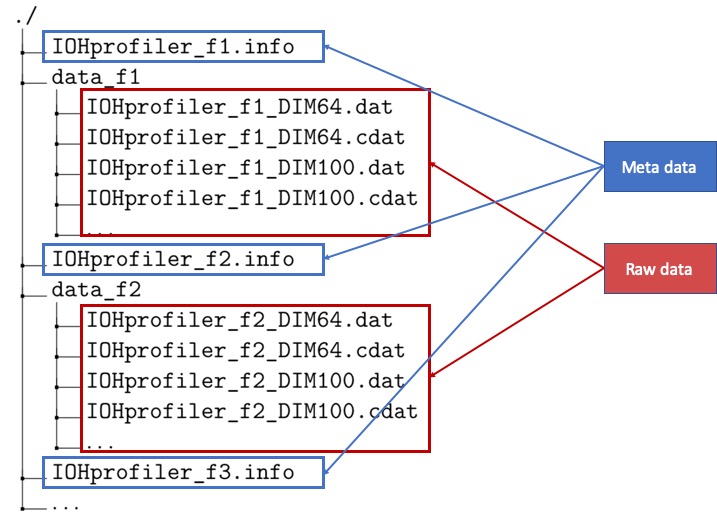
Generally, in the data folder (./ here), the following files are mandatory for IOHanalyzer:
- Meta-data (e.g., IOHprofiler_f1.info) summarizes the algorithmic performance for each problem instance, with naming the following naming convention:
IOHprofiler_f<
function ID>[_function name].info- Here, <
function ID> is required. [_function name] is optional. function ID: can take either an integer or a string as its value.function nameis only optional and is typically when the function ID is an integer.
- Here, <
- Raw-data (e.g., IOHprofiler_f1_DIM100.dat) are CSV-like files that contain performance information indexed by the running time. Raw-data files are named in the similar manner as with the meta-data:
IOHprofiler_f<
function ID>_DIM_<dimension>.[t|i|c]datdimensionmust be an integer.- [t|i|c] indicates three choices for this option.
- Using IOHexperimenter, you could produce four types of raw data files: *.dat, *.idat, *.tdat, and *.cdat, which share exactly the same format and only differ in the logging events at which data are recorded.
Meta-data
IOHexperimenter version 0.3.2 and below:
The meta data are implemented in a format that is very similar to that in the COCO/BBOB data sets. Note that one meta-data file can consist of several dimensions. Please see the detail below. An example is provided as follows:
suite = 'PBO', funcId = 10, DIM = 100, algId = '(1+1) fGA'
%
data_f10/IOHprofiler_f10_DIM625.dat, 1:1953125|5.59000e+02,
1:1953125|5.59000e+02, 1:1953125|5.59000e+02, 1:1953125|5.54000e+02,
1:1953125|5.59000e+02, 1:1953125|5.64000e+02, 1:1953125|5.54000e+02,
1:1953125|5.59000e+02, 1:1953125|5.49000e+02, 1:1953125|5.54000e+02,
1:1953125|5.49000e+02
suite = 'PBO', funcId = 10, DIM = 625, algId = '(1+1) fGA'
%
data_f10/IOHprofiler_f10_DIM625.dat, 1:1953125|5.59000e+02,
1:1953125|5.59000e+02, 1:1953125|5.59000e+02, 1:1953125|5.54000e+02,
1:1953125|5.59000e+02, 1:1953125|5.64000e+02, 1:1953125|5.54000e+02,
1:1953125|5.59000e+02, 1:1953125|5.49000e+02, 1:1953125|5.54000e+02,
1:1953125|5.49000e+02
...
A three-line structure is used for each dimension:
- The first line stores some meta-information of the experiment as (key, value) pairs. Note that such pairs are separated by commas. Three keys, funcId, DIM, and algId are case-sensitive and mandatory.
- The second line always starts with a single %, indicating what follows this symbol should be the general comments from the user on this experiment. By default, it is left empty.
- The third line starts with the relative path to the actual data file, followed by the meta-information obtained on each instance, with the following format:
$$\underbrace{1}_{\text{instance number}}:\underbrace{1953125}_{\text{#FE}}|\;\underbrace{5.59000\text{e+02}}_{\text{best-so-far f(x)}}$$
$\text{#FE}$ stands for the number of function evaluations.
IOHexperimenter version 0.3.3 and above:
The meta data are stored in standard ‘json’ format. The same data as above can be included.
{
"version": "0.3.5",
"suite": "unknown_suite",
"function_id": 12,
"function_name": "BentCigar",
"maximization": false,
"algorithm": {"name": "algorithm_name", "info": "algorithm_info"},
"attributes": ["evaluations", "raw_y"],
"scenarios": [
{"dimension": 2,
"path": "data_f12_BentCigar/IOHprofiler_f12_DIM2.dat",
"runs": [
{"instance": 1, "evals": 648, "best": {"evals": 648, "y": 8.395838469278655e-09, "x": [-0.8920357493234841, 3.9911997374078267]}},
{"instance": 1, "evals": 660, "best": {"evals": 659, "y": 5.715728502439972e-09, "x": [-0.8920705153336956, 3.9911996215977723]}},
{"instance": 1, "evals": 642, "best": {"evals": 637, "y": 3.8520665667764165e-09, "x": [-0.8919790763641989, 3.9912001624153266]}},
{"instance": 1, "evals": 612, "best": {"evals": 609, "y": 6.526032480998535e-09, "x": [-0.8919433049244551, 3.991200339301575]}},
{"instance": 1, "evals": 648, "best": {"evals": 646, "y": 6.063283992998331e-09, "x": [-0.8919741726505971, 3.9912000548845326]}},
{"instance": 1, "evals": 654, "best": {"evals": 654, "y": 3.4038668242174648e-09, "x": [-0.8920566463379289, 3.991199732092277]}}
]}
]
}
...
Raw-data
IOHexperimenter version 0.3.2 and below:
The format of raw data is illustrated by the example below (with dummy data records):
"function evaluation" "current f(x)" "best-so-far f(x)" "current af(x)+b" "best af(x)+b" "parameter name" ...
1 +2.95000e+02 +2.95000e+02 +2.95000e+02 +2.95000e+02 0.000000 ...
2 +2.96000e+02 +2.96000e+02 +2.96000e+02 +2.96000e+02 0.001600 ...
4 +3.07000e+02 +3.07000e+02 +3.07000e+02 +3.07000e+02 0.219200 ...
9 +3.11000e+02 +3.11000e+02 +3.11000e+02 +3.11000e+02 0.006400 ...
12 +3.12000e+02 +3.12000e+02 +3.12000e+02 +3.12000e+02 0.001600 ...
16 +3.16000e+02 +3.16000e+02 +3.16000e+02 +3.16000e+02 0.006400 ...
20 +3.17000e+02 +3.17000e+02 +3.17000e+02 +3.17000e+02 0.001600 ...
23 +3.28000e+02 +3.28000e+02 +3.28000e+02 +3.28000e+02 0.027200 ...
27 +3.39000e+02 +3.39000e+02 +3.39000e+02 +3.39000e+02 0.059200 ...
"function evaluation" "current f(x)" "best-so-far f(x)" "current af(x)+b" "best af(x)+b" "parameter name" ...
1 +3.20000e+02 +3.20000e+02 +3.20000e+02 +3.20000e+02 1.000000 ...
24 +3.44000e+02 +3.44000e+02 +3.44000e+02 +3.44000e+02 2.000000 ...
60 +3.64000e+02 +3.64000e+02 +3.64000e+02 +3.64000e+02 3.000000 ...
"function evaluation" "current f(x)" "best-so-far f(x)" "current af(x)+b" "best af(x)+b" "parameter name" ...
... ... ... ... ... ... ...
Note that, the columns and header of this format is regulated as follows:
- [mandatory] each separation line (the line that starts with “function evaluation”) serves as a separator among different independent runs of the same algorithm. Therefore, it is clear that the data block between two separation lines corresponds to a single run a triplet of (dimension, function, instance). The double quotation (”) in the separation line shall always be kept, and it cannot be replaced with single quotation (’).
- [mandatory] “function evaluation” the current number of function evaluations. In the target-based tracking file (*.dat), a block of records (representing one independent run, separated by the separation line) MUST end with the last function evaluation, if the target value is not reached in this run. This is critical for calculating the correct expected running time (ERT) value: please see the logging events section for the detail.
- [mandatory] “best-so-far f(x)” keeps track of the best function value observed since the beginning of one run.
- [optional] “current f(x)” stands for the function value observed when the corresponding number of function evaluations is consumed.
- [optional] The value stored under “current af(x)+b” and “best af(x)+b”, are so-called transformed function values obtained on each function instances that are generated by translating the original function in its domain and co-domain.
- [optional] In addition, a parameter value (named “parameter”) is also tracked in this example, and recording more parameter value is also facilitated. In case the quotation symbol is needed in the parameter name, please use the single quotation (’).
- Each data line should contain a complete record. Incomplete data records will be dropped when loading the data into IOHanalyzer.
- A single space or tab can be used (only one of them should be used consistently in a single data file), to separate the columns.
IOHexperimenter version 0.3.3 and above:
From version 0.3.3 onwards, the required data format has been simplified. We only track one value per problem by default, denoted as ‘raw_y’. This is the value which was denoted as ‘best-so-far f(x)’ above (and thus the one which enables comparison between instances). Additional parameters are added as additional columns, for example to track the position of the evaluated points in the search space.
evaluations raw_y x0 x1
1 6895156.6468390366 2.445611 6.633680
4 1070643.1062236333 0.281697 2.973091
7 22152.7909471173 -0.118144 4.143884
13 2779.8368648035 0.921224 3.927269
39 43.6691054900 2.280253 4.001168
63 10.7249333924 0.216650 3.999791
121 7.8764397895 1.642441 4.002590
134 6.6337496073 1.668475 4.003646
147 5.9562390837 1.486457 4.003567
182 5.6358495484 1.344023 4.003110
187 5.0142960630 1.346717 4.002277
306 5.0022631896 1.327907 4.001960
307 4.9245811271 1.324238 4.002101
313 4.8357629845 1.285684 4.001717
320 4.6821891454 1.247491 4.001509
324 4.5893709710 1.240789 4.001598
...
Logging Events
It is important to decide on which occasions data of the running algorithm should be recorded. On the one hand, it is straightforward to register the information for every function evaluation. However, this might lead to a huge amount of data to store, where some degree of data redundancy would occur since an iterative optimization heuristic would not make progress on every function evaluation. On the other hand, it is also possible to bookkeep the information of the algorithm once in a while, when an “interesting” event happens during the optimization process, e.g., the best function value found so far is improved, or the algorithm yields a numerical error. To make a trade-off here, four different data files (one mandatory and three optional ones) are provided in IOHexperimenter:
- [Mandatory] Target-based tracking (*.dat): a record is collected if an improvement on the “best-so-far f(x)” value is observed. Note that this data file is always generated. In this case, a block of records (representing one independent run) in the raw data MUST end with the last function evaluation, if the target value is not reached in this run. This is critical for calculating the correct expected running time (ERT) value: *.dat is an improvement-based tracking file, where one new line is written only if it is improving “best-so-far f(x)”. If the final target is actually reached, the line of the final FE will be recorded as the algorithm terminates in the same time. If the final target is not reached, we might loose the final number of FEs since the algorithm can stagnate and hence no new line will be written.
- [Optional] Interval tracking (*.idat): a record is collected every $\tau$-th function evaluation, where the interval $\tau$ can be controlled by the user. By default $\tau$ is set to zero and the interval tracking functionality is turned off.
- [Optional] Time-based tracking (*.tdat): a record is collected when the user-specified checkpoints on the running time are reached. These checkpoints are evenly spaced in the $\log_{10}$ scale, taking the following two forms: 1) ${v10^i \mid i = 0, 1,2, \ldots}$ with $v\in {1,2,5}$ by default and 2) ${10^{i / t} \mid i=0, 1,2,\ldots}$ with $t=3$ by default.
- [Optional] Complete tracking (*.cdat): a record is collected for every function evaluation, providing the highest granularity. This functionality is also turned off by default, as it might incur a large volume of data.
Links
GitHub Page
Email us
License
BSD 3-Clause
Cite us
Citing IOHprofiler
Developers
Diederick Vermetten
Jacob de Nobel
Furong Ye
Hao Wang
Ofer M. Shir
Carola Doerr
Thomas Bäck



